01
资料增加,结论没有增加
保存了十篇关于 AI 算力的文章,但判断 NVDA、GOOGL、MSFT、ORCL 谁更受益时,还是要重新翻一遍。
让 AI 不只是回答问题,而是持续积累判断力。它不是一个 App,也不是一个复杂的软件项目,而是一套由 Markdown、Git、Wiki、日志和 Agent Skills 组成的个人知识与决策操作系统。
很多人用 AI 的方式,还是停留在“问一个问题,得到一个答案”。
这当然有用。但如果你每天都在用 AI 读文章、看财报、做投资、写内容、复盘决策,很快会遇到一个更大的问题:
你今天让它分析一家公司,它能讲得头头是道。下个月同一家公司出了新财报,你再问它,它又从头分析一遍。它可能忘了你上次的仓位,忘了你当时的 Thesis,忘了你踩过的坑,也忘了哪些假设已经被证伪。
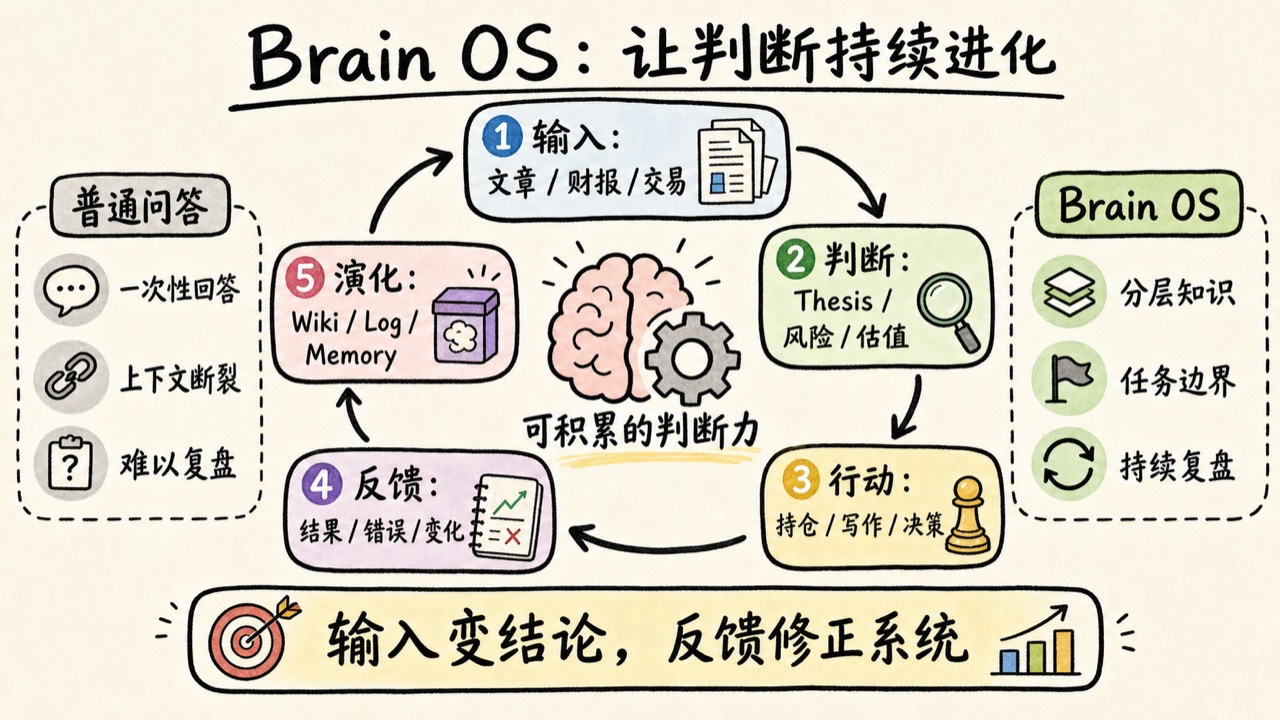
这不是模型不够强,而是我们没有给它一个可持续工作的系统。所以我搭了一个自己的 Brain OS。
它要解决的不是“如何保存更多资料”,而是一个更关键的问题:如何让输入变成判断,让判断指导行动,让行动产生反馈,再让反馈改进下一次判断。
过去我也用过很多知识管理工具。收藏文章、保存视频、摘录金句、写读书笔记、整理投资资料,看起来都很勤奋。但时间一长,会出现几个问题。
保存了十篇关于 AI 算力的文章,但判断 NVDA、GOOGL、MSFT、ORCL 谁更受益时,还是要重新翻一遍。
文章读完,摘要写得很好,但如果没有进入决策系统,它只是“看过”。
每次问 AI,它都能给出完整答案,但答案和过去的判断、仓位、失败教训之间没有天然连接。
投资最重要的不是事后看对错,而是回到当时:为什么这么判断?依据是什么?哪些信息后来被证明是错的?
如果没有记录,这些都只能靠记忆,而记忆非常不可靠。Brain OS 就是为了解决这些问题。
Brain OS 的底层逻辑很简单:原始资料不等于知识,摘要不等于判断,判断不等于行动,行动不等于复盘。这几层必须被区分开。
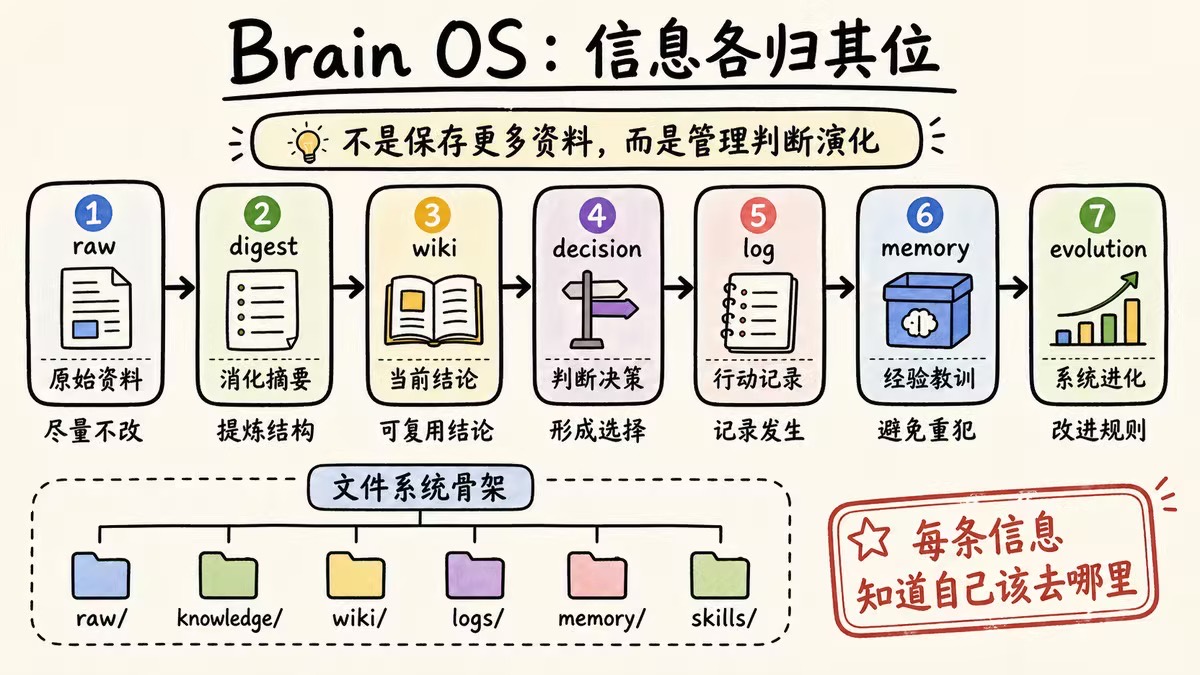
这套系统的重点不是“整理得好看”,而是让每一条信息知道自己该去哪里。
很多 AI 知识库的思路是 RAG,也就是每次用户提问时,系统重新检索相关资料,再交给模型回答。
RAG 很有用,但它有一个问题:每次都像重新开卷考试。它可以找到资料,但不一定知道哪些资料已经被我消化过,哪些结论已经被我采用过,哪些观点已经被证伪过。
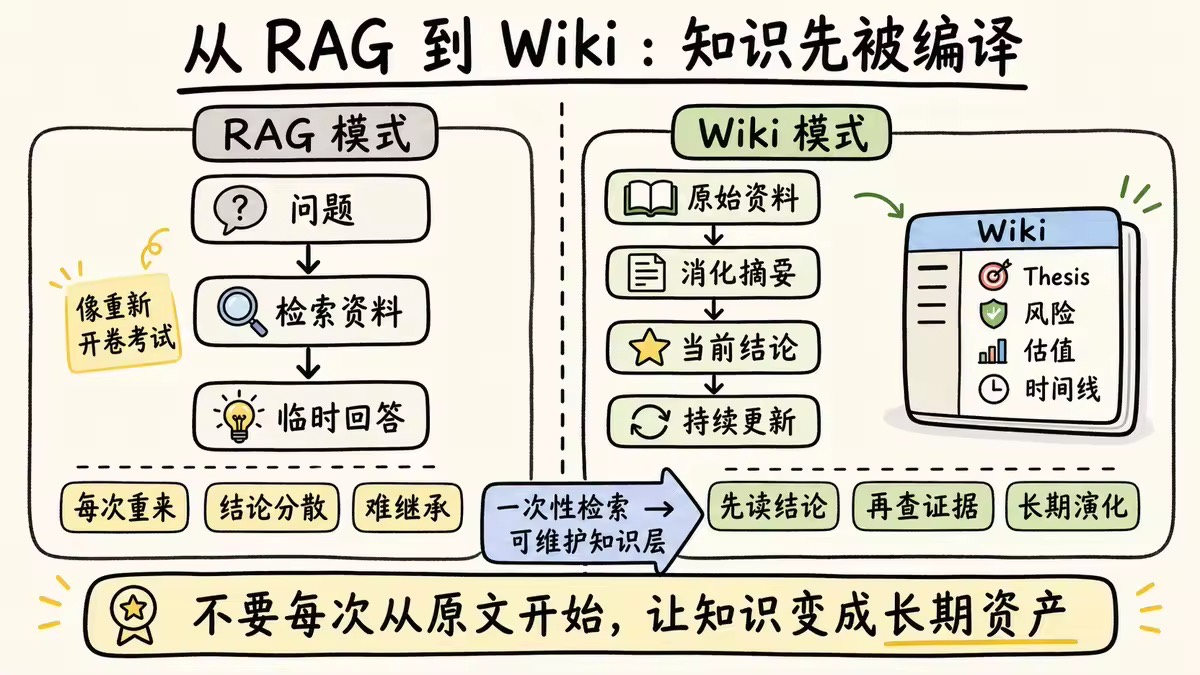
原始资料进入系统后,不是永远躺在文件夹里,而是经过消化,形成结构化结论,进入 `wiki/`。以后再问相关问题时,AI 不需要每次从原文开始读,而是先读 Wiki 中已经整理好的当前结论。
比如我对某个公司的判断,不是一篇孤立分析,而是一页长期维护的 Ticker Wiki:
这样,当新财报、新观点、新交易发生时,系统不是重新写一篇分析,而是更新这页 Wiki。
如果只是把文件放进不同目录,系统还不够强。真正让 Brain OS 可用的,是它给 AI 设定了一套工作机制。
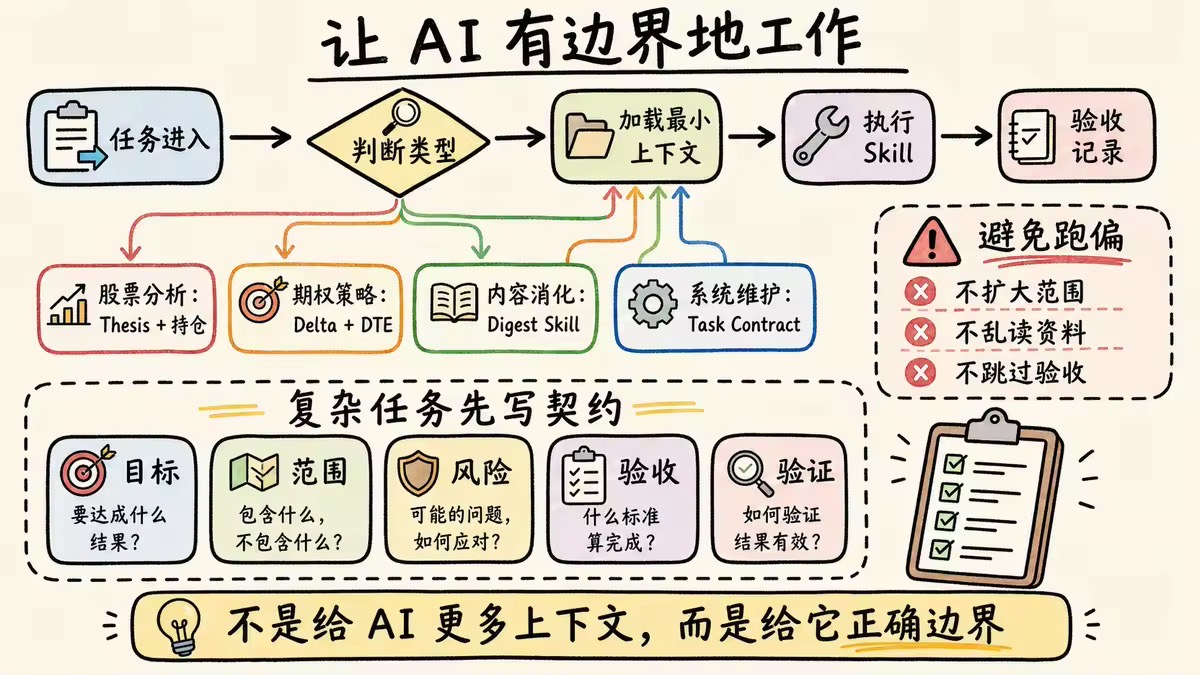
AI 最大的问题之一,是上下文膨胀。很多时候,我们以为给它更多资料,它就会更聪明。但实际情况是,无关信息太多,模型反而更容易混乱。
所以 Brain OS 规定:不同任务只加载对应上下文。股票分析读取投资规则、风险偏好、相关 Thesis;期权策略读取期权规则、持仓、Delta 和 DTE 约束;内容消化走 digest skill;系统维护先读 orchestration 和 task contract 模板。
涉及多文件修改、交易计划、系统升级时,Brain OS 不允许 AI 直接开干。它要先写一份任务契约:目标是什么,改哪些文件,不改哪些文件,验收标准是什么,风险是什么,怎么验证完成。
这一步看起来慢,实际上极大减少了跑偏。因为 AI 最常见的问题不是不会做,而是做着做着扩大范围,最后完成了一个看似厉害、但并不是你要的东西。
Brain OS 里有很多 Skill:股票分析、DCF 建模、期权监控、美投君内容总结、内容 digest、写作流水线、微信合规检查、周复盘、Wiki Lint、Wiki Query。
Skill 本质上不是一个文件,而是一种“可执行知识”。它告诉 AI:在什么场景下调用,读取哪些上下文,按什么步骤执行,输出什么格式,如何验证结果。这让 AI 从“临时发挥”变成“按流程工作”。
现在 Brain OS 的查询逻辑是分层的。先读 `wiki/index.md`,找到候选页面;再读页面的摘要和元数据;如果够用,就直接回答;如果不够,再精读正文;如果还不够,才回到原始资料。
知识库时间长了,一定会出现页面断链、结论过期、持仓和 Wiki 不一致、数字没有来源、失败教训没有回填、页面孤立存在等问题。
所以 Brain OS 有 `/wiki-lint`。它不是为了自动修改所有问题,而是先报告:哪里不一致,哪里缺来源,哪里可能过期,哪里需要人工确认。知识系统最危险的不是不知道,而是以为自己知道。
最近我对 Brain OS 做了一次重要升级。核心是让 `wiki/` 不只是一个页面集合,而是一个可以逐渐自组织的知识层。
Compiled Truth 是当前最可信结论;Timeline 是证据、操作、判断变化的时间线。读者先看到结论,复盘时还能看到结论如何形成。
区分 extracted、inferred、ambiguous,避免 AI 把所有句子都说得一样确定。
`wiki/.manifest.json` 记录哪个来源被处理过、什么时候处理、影响了哪些 Wiki 页面、来源是否变化。
未来系统看到一个新资料,不需要猜它有没有入库,而是可以检查 manifest。
在投资和决策场景里,确定性差异非常重要。一个用户明确提供的持仓数字,和一个模型基于公开信息推断出的行业判断,不能被当成同一类事实。
Brain OS 目前最成熟的能力集中在四类。
普通 Agent 更像一个聪明的临时顾问。Brain OS 更像一个会记账、会复盘、会维护知识库的长期合作伙伴。
这对投资尤其重要。因为投资最大的敌人不是没信息,而是事后合理化。
Brain OS 不是万能系统。它目前没有完整 UI,主要还是文件系统、Markdown 和 Agent 对话。它没有强数据库,也没有完整向量检索层。它不是企业级多人权限系统。
它不能自动保证所有事实正确,尤其是市场价格、财报数据、宏观指标这些会变化的信息,仍然需要实时验证。它也不能替代人做最终判断。
这套系统真正的价值,不是让 AI 自动替你做决定,而是让你做决定时更清楚自己依据什么、承担什么风险、未来如何复盘。
不要把所有东西都塞进一个“笔记”目录。
如果没有改变判断,就放在 digest。如果改变了判断,就更新 Wiki。如果影响了行动,就写入 log。
写一个自己的 `AGENTS.md` 或 `CLAUDE.md`。告诉 AI:哪些目录是什么用途,什么任务该读什么文件,什么情况必须先写任务契约,什么结论必须有来源,什么操作必须记录日志。
你不需要一次写完。系统应该和你的工作流一起演化。
AI 会越来越强。但越是这样,越不能只把它当成一个问答框。因为问答本身不积累。
真正能积累的是:你的判断框架、你的失败教训、你的行动记录、你的复盘习惯、你的知识结构。
Brain OS 的价值就在这里。它不是让 AI 取代大脑,而是让大脑的外部结构变得更清晰。
输入变结论。
结论指导行动。
行动产生反馈。
反馈修正系统。
系统提升判断。
AI 的上限,不只取决于模型,也取决于你给它怎样的工作环境。如果你只给它一个聊天框,它就是一个聪明的临时助手。如果你给它一个结构化、可追踪、可演化的系统,它才有机会成为长期合作者。